GPU的Scale Up互连成为炙手可热的话题,在2024年涌现了众多相关的行业讨论。站在阿里云的视角,什么样的技术以及生态才能满足云上智算集群的发展?为什么采用全新的Scale Up设计而不复用当前的以太网和RDMA技术呢?本文借着行业内的一些事件,对GPU超节点的Scale up互连的技术方向观点进行分享。
在GPU算力架构发展的历程和趋势中,我们意识到大模型的训练推理对显存容量以及带宽有不断增长的诉求,传统的GPU单机8卡方案已经不能满足业务发展的需要,更多卡组成超节点并具备大容量显存和低延的共享的解决方案才能满足大模型的需求。阿里云对行业技术方向进行评估后,于今年9月份发布了Alink Sytem开放生态和AI Infra 2.0服务器系统,其中底层互连协议部分兼容国际开放标准UALink协议。
10月29日,UALink联盟正式发布,并开启新成员邀请,发起成员包括AMD、AWS、Astera Labs、Cisco、Google、HPE、Intel、Meta 和Microsoft。其中相对于5月份的首次披露的成员,博通消失了,取而代之的是AWS和Astera Labs。其中AWS的加入引人遐想,因为AWS一向低调,很少参与协议组织。这次AWS躬身入局UALink联盟也展示了其对于GPU Scale Up互连需求的思考,以及对于UALink原生支持GPU互连这个技术方向的认同。下面,我们对于Scale up方向的思考做一些展开论述。
智算集群的互连架构
当前智算集群内,围绕着GPU存在三大互连,分别是业务网络互连、Scale Out网络互连、Scale Up网络互连,它们分别承载了不同的职责:跨业务、集群内、超级点GPU之间连通性。随着AI应用的爆发,推理的GPU规模最终会大大超过训练,由于推理服务同时追求业务请求的低延迟和高吞吐,Scale Up互连技术对于智算超节点意义重大,Scale Up主要是面向大模型推理服务以及兼顾训练。
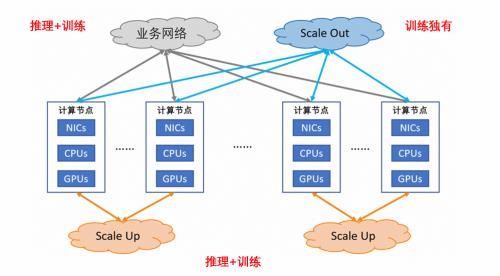
-业务网络互连:承载的是诸如需要计算的输入数据,输出结果,以及在各类存储系统中的模型参数、checkpoint等。需要进行极大范围的互连,并且和云上的存储、业务接口等互通,采用以太网技术,通常支持各类RDMA。
- Scale Out网络互连:训练的DP、PP并行计算切分流程,通常要把集群横向扩展到超多的GPU机柜,当前的训练规模已经发展到10w卡,目前国际的标准趋势是,采用专门优化的以太网技术UEC(Ultra Ethernet Consortium)协议。
- Scale Up网络互连:以推理的大显存并行计算流量和训练的张量并行(TP)以及专家并行(MoE)流量为主,有在网计算的需求(可以对All reduce在Switch节点上进行加速)。互连规模在未来很多年内都会维持在单柜72~80个GPU,从模型大小和推理需求的发展来看,当前规划能满足很长一段时间的需求。
超节点内部Scale Up互连:注定和设备深度绑定的协议
如何定义一个超节点的边界?这个边界就是网卡。超节点外的以太网是面向连接的设计,实现大面积的连通,超节点内的是面向计算的设计,实现的是部件间的协同。
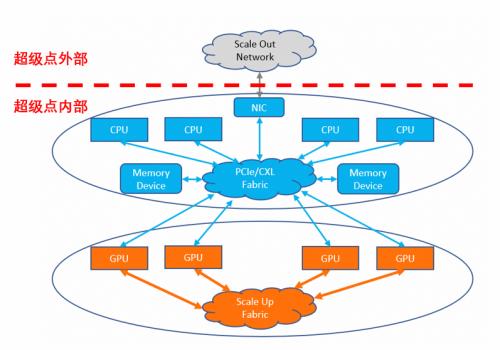
超节点内通过部件之间深度的耦合,实现了高效协同(包括效率、编程习惯等),这个耦合带来了性能(如带宽、延迟等),特性(内存共享、设备中断等)的需求,在过去很长一段时间内的典型技术是PCIe,它很好的解决了以CPU为中心的互连问题,几乎全部的服务器设备都是PCIe接口的。
当数据中心主要计算类型发生变化的时候,新的挑战出现了,围绕GPU为中心的计算带来了新的挑战:
-面向GPU的语义支持:GPU是超众核架构,其在线程调度机制,以及核心的利用率考量上和CPU有着显著的区别。CPU的外设交互模式及RDMA交互模式等,无法有效的满足GPU的访存特性和性能要求。和这个使用模式比较类似的是CXL(Compute Express Link,通用计算的内存扩展技术)的使用方式,但CXL在此场景下也存在局限性,比如大量内存一致性特性支持的开销,以及前向兼容PCIe所有协议栈带来的大量冗余特性。
-超高性能诉求:Scale Up相对于Scale Out和业务网络需要更高一个数量级(10倍以上)的带宽。由于GPU算力的狂飙,在当前的算力水平下,Blackwell这一代配置了双向共1.8T的算力,这意味着即使采用224g的phy,单芯片也需要双向共72个serdes差分对,整机柜需要数千根。。如果采用类似网卡的外置控制器方案,在功耗,延迟、稳定性等等都具有极大的劣势。Scale Up互连采用GPU直出,将所有的控制器植入GPU内部是不可避免的选择。
为什么采用全新的Scale Up协议而不复用已有的协议?
Scale UP互连是用于GPU和GPU 互连,是做更大芯片扩展的服务器,是内存和显存共享访问的语义,特点是极低延迟和大带宽,规模在柜内,可扩展为多柜到百芯片级(只是一种能力保留,但是未来很多年都看不到应用),是独立Fabric连接,完全不同于以太网。
Scale Out互连是用于服务器之间是基于网卡+交换机的集群互连,是以太网协议,规模在万级以上,普适的互连。
国际的主流厂商,尤其是云计算为代表的应用厂商都积极加入UALink,代表了一个广泛的观点,对于Scale Up,是有价值也有必要从底层协议到系统硬件进行重新设计的,目前业界主流的GPU芯片厂家都会考虑Scale Up采用独立的Link技术,不会和Scale Out合并设计。
特性维度
GPU+AI有着显著的特点,GPU是超多核的编程模型,和擅长通用性的CPU不同,需要使用到大量的内存语义(load/store)访问,同时由于各个GPU之间需要彼此使用HBM的内存,对跨芯片访问带宽和时延有显著的高要求。
其次Scale Up相对于Scale Out和业务网络需要更高一个数量级(10倍以上)的带宽,同时由于对于延迟的需求,需要采用GPU芯片直出互连的设计,协议的轻量化设计具备极大的价值,意味着可以将宝贵的芯片面积节省给GPU的计算核心、更高的IO集成能力、更低的功耗。
互连范围
Scale Up互连注重的是大模型的应用,从模型需求和互连分层的角度来说,Scale Up的互连域是一个独立高性能低延迟内存共享访问的互连域,单柜规模在72~80个GPU,保留百级的扩展能力(未来很多年都看不到应用),节点访问都是显存访问(load/store),性能和延迟的第一要素,完全不需要采用过于复杂的协议,这个是Scale Out的以太网完全做不到的,如果以太网可以做到,其实就已经简化到和Scale Up一样了,也就不是以太网了,脱离了以太网大规模普适的根本。
当前行业共识和UALink协议联盟发展
业界发展最早和最成熟的是NVDIA的NVLink技术,然而NVLink并不是开放生态,鉴于此,各家主要厂商或形成了闭环的自有协议方案(如谷歌TPU的OCS+ICI架构及AWS的NeuronLink)。当前行业中实际主流的,都采用的是自有技术,然而各家的演进成本都很高。
考虑到针对终态进行设计,以及共同对抗行业垄断的目的,AMD将其迭代多年的Infinity Fabric协议贡献出来,促成UALink联盟的成立,希望在更多行业伙伴的助力下,持续发挥原生为GPU互连场景设计的优势,使其成为行业的开放标准。
考虑到技术特点和开放生态给云计算公司将带来技术竞争力和供应链等全方位的优势,UALink在发布之后快速得到各家的青睐,尤其是原持有自有协议方案的公司,也积极加入其中。截止11月11日,UALink联盟已有三十余家厂商加入,并在持续扩展中;且涵盖了云计算和应用、硬件、芯片、IP等产业全生态。
当前国际业界已经形成共识:在开放协议领域,以UALink为代表的Scale Up协议和UEC为代表的Scale Out协议,共同支持AI集群互连基础协议的演进。
阿里的Alink System:原生支持AI场景的Scale Up开放生态
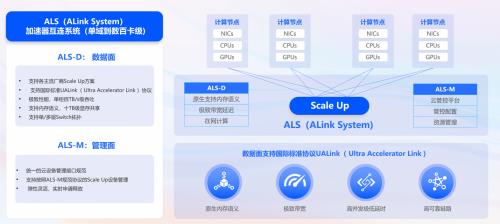
ALS(Alink System,加速器互连系统)是阿里云目前主导的开放生态,解决Scale Up互连系统的行业发展规范问题。ALS将在系统层面同时支持UALink国际标准并兼容封闭方案。ALS包括ALS-D数据面和ALS-M管控面两个主要组成部分。ALS-D在UALink上补充在网计算加速等特性,并支持Switch组网模式,其主要特点包括:
-性能维度,极致优化协议以达到最小的成本实现极致的性能。在协议格式、重传方案等维度的设计上充分考虑工程的性能优化,可对报文以极低的延迟进行解析、转发,从而具备端到端的低时延,并且在实现层面可以节省大量的芯片面积。
-组网维度,考虑到并行计算的发展,在新的并行模式(如EP)下需要更强大的点对点通信能力,ALS-D系统定义了基于Switch硬件连接方案,并且支持单层和二层的互连拓扑,提供多至数百/数千节点的互连,可以在各级连接方案中维持1:1的带宽收敛比,实现具备PB级的显存共享,为AI计算的通信操作提供灵活的规模支撑。
互连的管控运维也是系统设计的重要组成部分,ALS-M的目标是为不同的芯片方案提供标准化的接入方案,符合此规范的设备均可灵活接入应用方系统。无论是对于开放生态(如UALink系统),还是封闭厂商,ALS使用统一的软件接口。同时,ALS-M为云计算等集群管理场景,提供单租、多租等灵活和弹性的配置能力。
ALink System的目标是,聚焦GPU算力需求、驱动云计算定义的开放生态,形成智算超节点的竞争力。
转载请注明来自语言学习,本文标题:《从UALink近期发展再看GPU Scale Up的互连方向》