将负载转移到 GPU,能让您在本地 RTX AI PC 和工作站上使用超大模型。
编者注:本文属于《AI 解密》系列栏目,该系列的目的是让技术更加简单易懂,从而解密 AI,同时向 GeForce RTX PC 和 NVIDIA RTX 工作站用户展示全新硬件、软件、工具和加速特性。
大语言模型 (LLM) 正在重塑生产力。它们能够起草文件、汇总网页,并基于大量数据进行了训练,从而准确回答几乎任何主题的问题。LLM 是生成式 AI 领域许多新兴场景的核心,比如数字助手、交互式数字人和客服智能体。
许多最新 LLM 可在 PC 或工作站上本地运行。出于诸多原因,这样做非常有用:用户可以在设备上保持对话和内容的私密性,在没有互联网的情况下使用 AI,或直接利用其系统中的强大 NVIDIA GeForce RTX GPU。由于规模和复杂性问题,其他模型不适合用于本地 GPU 的视频显存 (VRAM),并需要使用大型数据中心的硬件。
但是,在搭载 RTX 的 PC 上,可以使用称为 GPU 卸载的技术,在本地加速处理数据中心级模型的部分提示词。这样,用户就可以从 GPU 加速中受益,而不受 GPU 显存限制。
规模和质量与性能取舍
通常用户需要在模型规模和回复质量与性能之间做出权衡。一般来说,大型模型会提供更高质量的回复,但运行速度更慢。使用小型模型时,性能有所提升,而质量会降低。
这种权衡并不总是显而易见。某些情况下,性能可能比质量更加重要。对于内容生成等用例,一些用户可能会优先考虑准确性,因为其任务可以在后台运行。同时,会话助理需要快速运行,同时还需要提供准确的回复。
高准确度的 LLM 为数据中心所设计,其大小高达几十 GB,可能无法放进 GPU 显存。在以前,这样的模型可能无法利用 GPU 加速。但是,GPU 卸载允许用户分别在 GPU 和 CPU 上使用一部分 LLM,这有助于用户更大限度地利用 GPU 加速功能,而不论模型的规模大小。
利用 GPU 卸载和 LM Studio 优化 AI 加速
LM Studio 是一个便于用户在其台式电脑或笔记本电脑下载和部署 LLM 的应用,它具有易于使用的界面,还能对模型实现高度定制。LM Studio 基于 llama.cpp 而构建,因此进行了全面优化,可与 GeForce RTX 和 NVIDIA RTX GPU 搭配使用。
借助 LM Studio 和 GPU 卸载,即使无法将这类模型完全加载到 VRAM 中,用户仍可利用 GPU 加速来提升本地部署 LLM 的性能。
使用 GPU 卸载,LM Studio 可将模型分为更小的块或“子图”,代表模型架构中不同的层级。子图不会永久固定在 GPU 上运行,而是根据需要加载和卸载。利用 LM Studio 的 GPU 卸载滑块,用户可以决定其中多少个层由 GPU 进行处理。
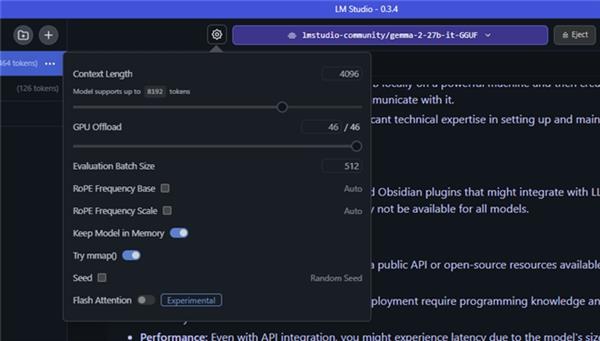
通过 LM Studio 界面,可以轻松决定应将多大比例的 LLM 加载到 GPU。
比如我们将这种 GPU 卸载技术用在 Gemma 2 27B 这类大型模型上。“27B”指模型中的参数数量,通过它可以估计运行该模型所需的内存量。根据 4 位量化技术 — 一种在不显著降低精度的情况下缩小 LLM 规模的技术,每个参数占用半个字节的内存。这意味着该模型约需要 135 亿字节或 13.5 GB 内存,再加上一些一般大小在 1-5GB 的额外开销。
因此,在 GPU 上完全加速此模型需要 19GB 的 VRAM,GeForce RTX 4090 台式电脑 GPU 可以做到。利用 GPU 卸载,该模型可以在装有低端 GPU 的系统上运行,并且仍然从加速功能中受益。
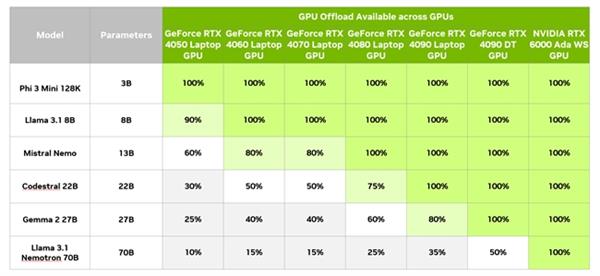
上表显示了如何在一系列 GeForce 和 NVIDIA RTX GPU 上运行数种规模从小到大的常用模型。对于每种组合,都指明了最大 GPU 卸载级别。请注意,即使采用 GPU 卸载,用户仍然需要足够的系统 RAM 来满足整个模型的需求。
在 LM Studio 中,对比纯 CPU 运行,我们可以评估不同级别的 GPU 卸载对性能的提升。下表显示了在 GeForce RTX 4090 台式电脑 GPU 上使用各种卸载级别处理同一个输入的结果。
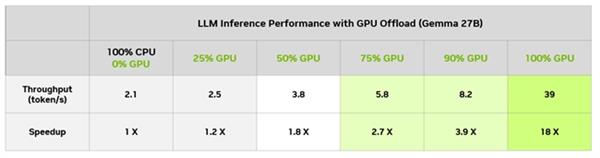
根据卸载到 GPU 的模型百分比,用户可以看到,与仅在 CPU 上运行相比,吞吐量性能有所提高。对于 Gemma 2 27B 模型,随着 GPU 用量增加,性能从较低的 2.1 token/s 开始,逐渐提升到更可用的速度。这样用户就能享受之前无法享受到的大型模型的更高性能。
在这个特定模型上,相比于仅在 CPU 上运行,即使是 8GB GPU 的用户也可以实现显著的速度提升。当然,8GB GPU 始终可以运行较小的能装进显存的模型,并获得全面的 GPU 加速。
实现最佳平衡
LM Studio 的 GPU 卸载功能是一个强大的工具,可帮助充分发挥专为数据中心设计的 LLM 的潜力,例如在 RTX AI PC 上本地运行 Gemma-2-27B。这样,就可以在由 GeForce RTX 和 NVIDIA RTX GPU 提供算力支持的整个 PC 系列上运行更大、更复杂的模型。
请下载 LM Studio 以在大型模型上试用 GPU 卸载,或体验在 RTX AI PC 和工作站上本地运行一系列 RTX 加速 LLM。
请订阅《解码 AI》时事通讯,我们每周都会将新鲜资讯直接投递到您的收件箱。
###
转载请注明来自语言学习,本文标题:《如何在 RTX 上通过 LM Studio 在本地加速运行大型 LLM》